

Check out our video on this topic over on YouTube:
RAG vs. CAG: How Cache-Augmented Generation Really Works
There’s a lot of buzz lately about CAG—Cache-Augmented Generation, and for good reason. Some are calling it a faster, simpler replacement for traditional RAG pipelines. Others are wondering if it’s time to ditch retrieval altogether.
The reality? It’s more nuanced, and more exciting, than a simple swap. CAG isn’t a RAG replacement; it’s a powerful tool that changes how context is handled inside a RAG system. To understand why that matters, let’s unpack how each one works, and where they work best together.

What RAG Actually Does
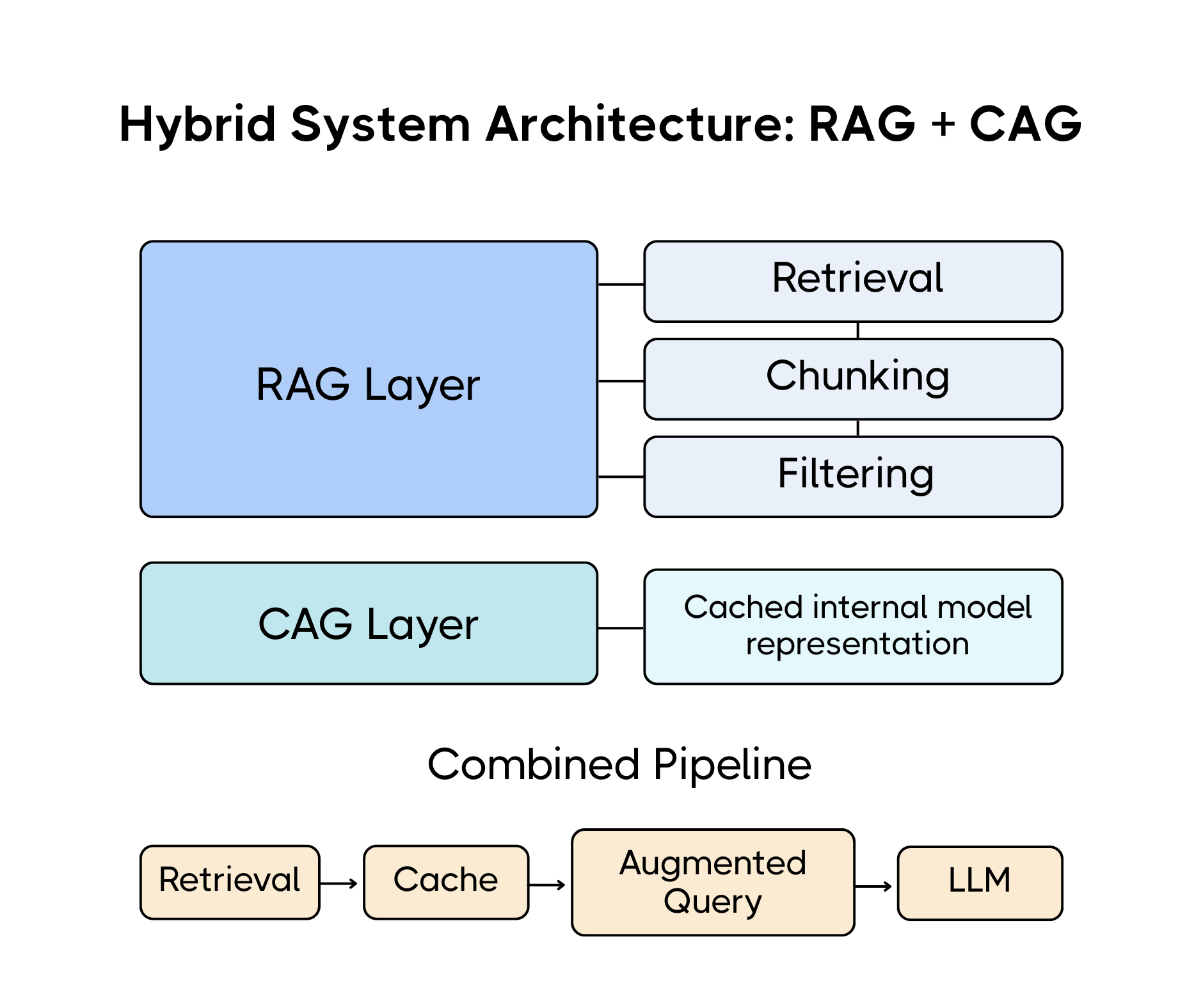
RAG, or Retrieval-Augmented Generation, is the foundation of many production AI systems today. It allows users to ask questions about their own private data, not just what the model was pre-trained on.
Here’s the basic flow:
- A user asks a question.
- The system searches a private document database, typically chunked and indexed in a vector store.
- It retrieves the most relevant chunks, constructs an augmented prompt that includes both the query and those chunks, and sends it to the language model.
This architecture is powerful: it enables reasoning over private, dynamic information without retraining the model, and it keeps costs down by only sending minimal context at inference time.
But RAG isn’t simple. It involves multiple components: parsing, chunking, embedding, indexing, retrieval—all of which introduce points of failure.
What CAG Changes
CAG, or Cache-Augmented Generation, doesn't replace retrieval, it changes how context is delivered to the language model.
Instead of retrieving document chunks and injecting them as plain text at inference time, CAG works by first feeding the documents through the model ahead of time. The key difference? It doesn’t store the raw documents, it stores the model’s internal understanding of them.
This internal representation, how the model “thinks” about the data, is saved in a cache.
When a user later asks a question, the system doesn’t need to re-feed the original documents. It simply accesses the cached understanding and combines it with the question. This leads to faster response times, lower compute, and fewer moving parts during generation.
Think of it as saving the model’s memory of a document rather than making it re-read it every time.

Where CAG Works—and Where It Doesn’t
CAG shines in scenarios where:
- The relevant context fits within the model’s context window.
- You’re working with static or semi-static documents like knowledge bases or overviews.
- You want to reduce inference cost and avoid reprocessing the same data repeatedly.
But CAG has two major limitations:
1. Context windows are still limited.
Despite headlines about 2M+ token windows from models like Gemini or LLaMA, most practical use cases today are operating within 32K–128K tokens. That’s not enough for organizations with millions of pages of documents. In those cases, retrieval is still necessary to scope what gets cached in the first place.
2. Bigger ≠ better.
Stuffing more into a context window doesn’t always improve results. Long documents can lead to degraded model performance. Important details in the middle may be skipped, misinterpreted, or ignored. In fact, RAG’s chunking and retrieval approach often outperforms brute-force summarization when accuracy matters.
So while CAG changes how context is passed into the model, it doesn’t eliminate the need for smart retrieval, especially in large, dynamic environments.
The Myth of RAG vs. CAG
It’s tempting to frame this as a battle: RAG vs. CAG. But that’s a false dichotomy.
RAG and CAG address different challenges in a modern AI system:
- RAG helps you search across a massive, external knowledge base. It’s like long-term memory, scanning millions of documents to pull what matters now.
- CAG is about making inference more efficient. It stores the model’s prior understanding, making it more like short-term memory, ready to respond instantly when questions arrive.
Used together, they create a more powerful system:
- Use RAG to identify what content matters.
- Use CAG to remember how the model processed that content.
One helps you find the signal. The other helps you keep it close.

What to Build Now
There’s real excitement around long context models. But the research being cited, often limited to 32K–64K token windows, isn’t yet aligned with enterprise-scale needs.
If you’re a bank, hospital, or Fortune 500 company, you’re likely working with millions of documents. Even the biggest context windows can’t eliminate the need for smart indexing, filtering, and search.
That’s where a hybrid approach shines.
- Let RAG handle breadth, pulling in the most relevant content across a massive corpus.
- Let CAG handle depth, storing the model’s contextual memory for efficient reuse.
This combination reduces latency, lowers cost, and increases reliability. It’s not about choosing RAG or CAG. It’s about knowing when to use each, and how they work best together.
Final Thoughts
CAG is not a silver bullet, it’s a meaningful step forward. It offers a smarter, more scalable way to handle repeated queries and long-lived document memory. For small and medium-sized use cases, it can massively streamline LLM applications. But for larger workloads, retrieval still plays a critical role.
In the end, the best systems won’t pick sides.
They’ll combine retrieval and caching, long-term and short-term memory, structured search and cached insight. The future isn’t RAG vs. CAG.
It’s RAG plus CAG.


